
每个程序员都应该知道的 CPU 知识:NUMA – 知乎 (zhihu.com)
什么是 NUMA?
早期的计算机,内存控制器还没有整合进 CPU,所有的内存访问都需要经过北桥芯片来完成。如下图所示,CPU 通过前端总线(FSB,Front Side Bus)连接到北桥芯片,然后北桥芯片连接到内存——内存控制器集成在北桥芯片里面。
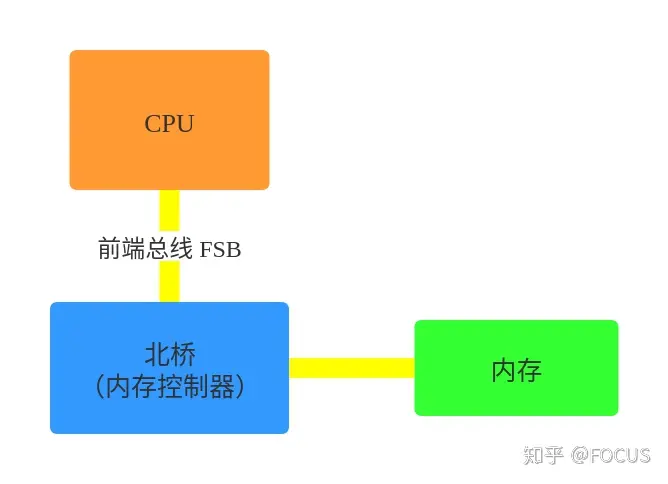
这种架构被称为 UMA1(Uniform Memory Access, 一致性内存访问 ):总线模型保证了 CPU 的所有内存访问都是一致的,不必考虑不同内存地址之间的差异。
在 UMA 架构下,CPU 和内存之间的通信全部都要通过前端总线。而提高性能的方式,就是不断地提高 CPU、前端总线和内存的工作频率。
后面的故事,大部分人都很清楚:因为物理条件的限制,不断提高工作频率的路子走不下去了。CPU 性能的提升开始从提高主频转向增加 CPU 数量(多核、多 CPU)。越来越多的 CPU 对前端总线的争用,使前端总线成为了瓶颈。为了消除 UMA 架构的瓶颈,NUMA2(Non-Uniform Memory Access, 非一致性内存访问)架构诞生了:
- CPU 厂商把内存控制器集成到 CPU 内部,一般一个 CPU socket 会有一个独立的内存控制器。
- 每个 CPU scoket 独立连接到一部分内存,这部分 CPU 直连的内存称为“本地内存”。
- CPU 之间通过 QPI(Quick Path Interconnect) 总线进行连接。CPU 可以通过 QPI 总线访问不和自己直连的“远程内存”。
和 UMA 架构不同,在 NUMA 架构下,内存的访问出现了本地和远程的区别:访问远程内存的延时会明显高于访问本地内存。
NUMA 的设置
Linux 有一个命令 numactl3 可以查看或设置 NUMA 信息。
- 执行
numactl --hardware可以查看硬件对 NUMA 的支持信息:
# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
node 0 size: 96920 MB
node 0 free: 2951 MB
node 1 cpus: 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
node 1 size: 98304 MB
node 1 free: 33 MB
node distances:
node 0 1
0: 10 21
1: 21 10
- CPU 被分成 node 0 和 node 1 两组(这台机器有两个 CPU Socket)。
- 一组 CPU 分配到 96 GB 的内存(这台机器总共有 192GB 内存)。
- node distances 是一个二维矩阵,node[i][j] 表示 node i 访问 node j 的内存的相对距离。比如 node 0 访问 node 0 的内存的距离是 10,而 node 0 访问 node 1 的内存的距离是 21。
- 执行
numactl --show显示当前的 NUMA 设置:
# numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
cpubind: 0 1
nodebind: 0 1
membind: 0 1
- numactl 命令还有几个重要选项:
--cpubind=0: 绑定到 node 0 的 CPU 上执行。--membind=1: 只在 node 1 上分配内存。--interleave=nodes:nodes 可以是 all、N,N,N 或 N-N,表示在 nodes 上轮循(round robin)分配内存。--physcpubind=cpus:cpus 是 /proc/cpuinfo 中的 processor(超线程) 字段,cpus 的格式与 –interleave=nodes 一样,表示绑定到 cpus 上运行。--preferred=1: 优先考虑从 node 1 上分配内存。
- numactl 命令的几个例子:
# 运行 test_program 程序,参数是 argument,绑定到 node 0 的 CPU 和 node 1 的内存
numactl --cpubind=0 --membind=1 test_program arguments
# 在 processor 0-4,8-12 上运行 test_program
numactl --physcpubind=0-4,8-12 test_program arguments
# 轮询分配内存
numactl --interleave=all test_program arguments
# 优先考虑从 node 1 上分配内存
numactl --preferred=1
测试 NUMA
#include <sys/time.h>
#include <iostream>
#include <string>
#include <vector>
int main(int argc, char** argv) {
int size = std::stoi(argv[1]);
std::vector<std::vector<uint64_t>> data(size, std::vector<uint64_t>(size));
struct timeval b;
gettimeofday(&b, nullptr);
# 按列遍历,避免 CPU cache 的影响
for (int col = 0; col < size; ++col) {
for (int row = 0; row < size; ++row) {
data[row][col] = rand();
}
}
struct timeval e;
gettimeofday(&e, nullptr);
std::cout << "Use time "
<< e.tv_sec * 1000000 + e.tv_usec - b.tv_sec * 1000000 - b.tv_usec
<< "us" << std::endl;
}
# numactl --cpubind=0 --membind=0 ./numa_test 20000
Use time 16465637us
# numactl --cpubind=0 --membind=1 ./numa_test 20000
Use time 21402436us
可以看出,测试程序使用远程内存比使用本地内存慢了接近 30%
Linux 的 NUMA 策略
Linux 识别到 NUMA 架构后,默认的内存分配方案是:优先从本地分配内存。如果本地内存不足,优先淘汰本地内存中无用的内存。使内存页尽可能地和调用线程处在同一个 node。
这种默认策略在不需要分配大量内存的应用上一般没什么问题。但是对于数据库这种可能分配超过一个 NUMA node 的内存量的应用来说,可能会引起一些奇怪的性能问题。
下面是在网上看到的的例子:由于 Linux 默认的 NUMA 内存分配策略,导致 MySQL 在内存比较充足的情况下,出现大量内存页被换出,造成性能抖动的问题。
- The MySQL “swap insanity” problem and the effects of the NUMA architecture4
- A brief update on NUMA and MySQL5
参考资料
- UMA(Uniform Memory Access, 一致性内存访问):https://en.wikipedia.org/wiki/Uniform_memory_access
- NUMA(Non-Uniform Memory Access, 非一致性内存访问):https://en.wikipedia.org/wiki/Non-uniform_memory_access
- numactl:https://linux.die.net/man/8/numactl
- The MySQL “swap insanity” problem and the effects of the NUMA architecture:http://blog.jcole.us/2010/09/28/mysql-swap-insanity-and-the-numa-architecture/
- A brief update on NUMA and MySQL:http://blog.jcole.us/2012/04/16/a-brief-update-on-numa-and-mysql/
- NUMA架构的CPU — 你真的用好了么?:http://cenalulu.github.io/linux/numa/
- Thread and Memory Placement on NUMA Systems: Asymmetry Matters:https://www.usenix.org/conference/atc15/technical-session/presentation/lepers
- NUMA (Non-Uniform Memory Access): An Overview:https://queue.acm.org/detail.cfm?id=2513149
- NUMA Memory Policy:https://www.kernel.org/doc/html/latest/admin-guide/mm/numa_memory_policy.html
- What is NUMA?:https://www.kernel.org/doc/html/latest/vm/numa.ht